Internet Explorer As A Development Platform?
META tags: What they are and how they work
HTML #5 - Using feedback forms
HTML #4 - Advanced Page Layout
You are here: irt.org | Articles | HTML | Stop! Is Your HTML Document Valid? [ previous next ]
Published on: Friday 30th April 1999 By: Pankaj Kamthan
Be conservative in what you produce; be liberal in what you accept.
HTML authoring can lead to the possibility of errors. These errors are similar to that which can occur in using typesetting languages (e.g., LaTeX, which inspired HTML development). Such errors are not reflected in many browsers as they follow the second half of the above maxim in computer programming - by accepting HTML documents and trying to display them even if they are not valid HTML. Usually, this means that the browser will try to make educated guesses about what the author probably meant. It works ... sometimes.
The trend in HTML authoring is, unfortunately, an HTML-version of this second maxim:
If it ain't broken (i.e., the document is rendered "correctly"), why fix it?
This, however, hardly qualifies as "good" HTML authoring. Also, the problem is that different browsers (or even different versions of the same browser) will make different guesses about the same illegal construct in an invalid HTML document. The result is a document that will display correctly up to a certain point and then display incorrectly, or even stops abruptly. Even if the document does seem to display correctly in all browsers in existence at that time (testing which could be quite time consuming), there is no guarantee that it will do so in their future versions. It is also possible that some other author may use your document in his/her work, only to find it is incorrect.
These are some of the reasons why you want to follow the first half of the above maxim by making sure your documents are in valid HTML. The best way of doing that is by processing your documents through one or more HTML validators.
Standard Generalized Markup Language (SGML) is a meta-language, of which HTML is a "child". For our purposes, a DTD is simply a document that defines the syntax of an SGML-based language, such as HTML. An HTML document that conforms to a DTD is said to be valid corresponding to that DTD. Validation can have, besides DTD-conformance, other diverse viewpoints: we will restrict ourselves to syntactical, semantical (spelling in case of an HTML document), and stylistic.
In this article, we take a tour of most commonly used HTML validators, the choice being based on the different features they offer. Demos of these validators (which are referring CGI gateways to respective validators) are also included. Besides validation, we also consider how to make a document optimal. We assume here that the reader has some knowledge of HTML and basic experience with Emacs.
The HTML validators which we will be discussing, are given in the following table:
| SERVICE | URL | SUPPORTED DTDs | TYPE OF VALIDATION |
| W3C HTML Validation Service | http://validator.w3.org/ | HTML 3.2, 4.0, Other DTDs | Syntax, Style |
| HTMLChek | http://uts.cc.utexas.edu/~churchh/htmlchek.html | HTML 3.2 | Syntax |
| Weblint | http://www.cre.canon.co.uk/~neilb/weblint/ | HTML 3.2 | Syntax, Style |
| HTML Tidy | http://www.w3.org/People/Raggett/tidy/ | HTML 4.0 | Syntax (limited), Style, Structure |
| Doctor HTML | http://www2.imagiware.com/RxHTML/ | NA | Syntax (limited), Style, Structure |
W3C and WebTechs Validation Services operate directly from the HTML DTD, and both strictly obey the rules of SGML. HTMLChek and Weblint are
heuristic validators - they do not completely parse your HTML markup, but simply scan it looking for errors. The advantage of this is that
they are fast and can detect constructs that are valid HTML but considered "bad style", such as an <IMG> tag without an
ALT attribute; the disadvantage is that they can fail to detect certain errors.
Using a combination of validators is probably the best solution. Each has features that the others don't, and they complement each other well.
We will discuss the use of W3C and WebTechs Validation Services, Weblint and Doctor HTML. HTMLChek is mentioned here for its historical significance. We will not discuss it as it is slightly dated.
There are various online HTML validation services. Among these, the most notable and authoritative is the W3C HTML Validation Service.
The W3C HTML Validation Service is based on James Clark's nsgmls SGML parser and Weblint. It checks HTML documents for compliance with W3C HTML Recommendations and other HTML standards. It does not have a File Upload option (like WebTechs HTML Validation Service).
According to the W3C HTML 4.0 Recommendation, the document should begin with one of the following DOCTYPE declarations:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd"> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd"> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Frameset//EN" "http://www.w3.org/TR/REC-html40/frameset.dtd">
There is a list of other DTDs which are also supported. Source code for this service is also available for some UNIX platforms, which can be used to set-up an offline validation service. (This, however, is not straightforward; besides installing a myriad of prerequisite software, one has to download necessary DTDs which are retrieved by the SGML parser off the WWW.)
Enter the URL of the document to be validated:
Once your document has passed the W3C HTML Validation Service, you can place the following icon on it:
![]()
HTML Tidy is a utility to tidy up sloppy editing into nicely layed out markup. It also works well on the difficult to read markup generated by special-purpose HTML editors and conversion tools. It can help you identify how you can make your pages more accessible to people with disabilities. It also has support for all HTML 4.0 entities, internationalization (through various character encodings) and a limited XML 1.0 support.
HTML Tidy is able to fix up a wide range of problems and to bring to your attention things that you need to work on yourself. It provides the location of each problem found with the line number and column, and generates a list of such problems. It has limited validation capabilites. When there are problems that it can not handle, they logged as "errors" rather than "warnings".
For use of an offline version of HTML Tidy, see HTML Tidy Revisited.
CYAN is an online interface to HTML Tidy. It can check WWW pages for HTML 4.0 compliance while formatting tags according to your preferences. CYAN will then let you download a copy of the specified page with common errors fixed and point out rest of the errors.
Doctor HTML performs tests, which can be selected from a menu, and displays a report containing the syntax errors and stylistic suggestions. We quickly outline the most important features:
A detailed explanation of all the options in Doctor HTML and an FAQ are available. It does not have a File Upload option (like WebTechs HTML Validation Service).
Enter the URL that you wish Doctor HTML to examine and select the tests you wish it to perform in the form below.
Once your document has passed the Doctor HTML Service, you can place the following icon on it:
![]()
Even after an HTML document is validated, it may contain unnecessary characters. HTML Squisher is a script which optimizes your HTML document by removing those characters. By doing so, it shrinks the number of bytes in your HTML document and makes it download faster. Some of its useful features are:
There is, however, one disadvantage: a page that has been squished will not be very human-readable, though it should still be parsed by an HTML editor and will display in your WWW browser without difficulty. You can reformat the HTML into something relatively easy to edit using the HTML Formatter.
To squish an HTML page, enter the URL below and press the Squish button.
There are times when you are working offline, by choice or by force, and/or do not have access to the Internet. In such a case, it might be useful to have a facility of HTML validation offline on your own computer.
One solution is to use a syntax-checking HTML editor. Another is to an HTML syntax checker such as weblint. Many of the WYSIWYGU (What You See Is What You Get Unfortunately) graphical-editors (e.g., FrontPage 98, Netscape Composer) also overlook basic syntactical errors. Furthermore, some HTML authoring tools, generate HTML code which is completely contrary to the design goals of the language - they look at a document from the point of view of layout, and then mimic that layout in HTML, by often overusing certain tags (e.g., <BR>) or using proprietary tags (such as <FONT>). This renders them impractical to be recasted into other markup languages, such as eXtensible Markup Language (XML).
Weblint is a syntax and minimal style checker for HTML. It catches syntax errors, warns about "bad" HTML style practices and potential compatibility problems. It is implemented as a Perl script which picks fluff off HTML pages, much in the same way as traditional lint picks fluff off C programs. It is available for UNIX, Windows NT, Macintosh and OS/2. We describe here version 1.020.
The following checks are currently performed:
|
|
We will not discuss the details of installing weblint; for that you can refer to the readme file from the weblint distribution. The requirement is that you need to have Perl (4.036 or 5.004) on your system.
Files to be checked are passed on the command-line:
% weblint *.html
Warnings are generated similar to that of lint:
<filename>(line #): <warning>
For example:
index.html(5): malformed heading - open tag is <H1>, but closing is </H2>
For details of usage see the Weblint Man Page.
A Weblint gateway is an HTML form which lets you type in a URL and have it checked by weblint without having to install weblint locally, turning it into an online HTML validation service. One such (referer) gateway is available at Concordia University, Canada. For a comprehensive list, see the Weblint Gateways Page .
One advantage of using weblint for offline syntax checking is that you can use it in conjunction with a powerful editor such as Emacs.
Emacs is a widely and freely available editor distributed by the Free Software Foundation (FSF) and runs under a wide variety of operating systems. Emacs can be configured to HTML editing, for example, with the help of the html-helper-mode. For those who wish to learn more about Emacs, a list of references has been provided.
If you have installed Weblint on your system, you can use the weblint mode to check the validity of your HTML files within Emacs.
A copy of weblint mode is available at Concordia University, Canada. To use the mode, you need to add the following lines to your .emacs file after you have changed the path to the weblint directory accordingly:
(setq load-path (cons "path_to_weblint_directory/" load-path)) (autoload 'weblint "weblint" "Weblint syntax checker" t)
After creating and saving an HTML file, type:
M-weblint RET
to invoke the weblint mode and do the checking. The results of the checks are displayed in a separate window. You can then toggle back and forth between the windows to browse through the errors and warnings, and do the debugging. The above process can be repeated till you are satisfied with the state of the document.
HTML Tidy is available for Windows 95/NT (as a binary), Linux, MacOS, BeOS, and a variety of UNIX platforms. We will not discuss the details of installation. (It is straightforward on Windows 95, Linux and IRIX, on which it was tested.)
HTML Tidy runs on command-line with various options as
tidy [[options] filename]*
For a list of options and some representative examples, see the HTML Tidy page.
A GUI version of HTML Tidy, HTML-Kit, is also now available for Windows 95/98/NT. HTML-Kit can be used by experts as well as newcomers to HTML, who can benefit from HTML-Kit pointing out errors and improvements to the markup. It will also allow users to see which tags produce which effects. Figure 1 shows a snapshot of HTML-Kit in use with the URL http://www.irt.org. HTML-Kit can perform checks both with Tidy and CSE HTML Validator.
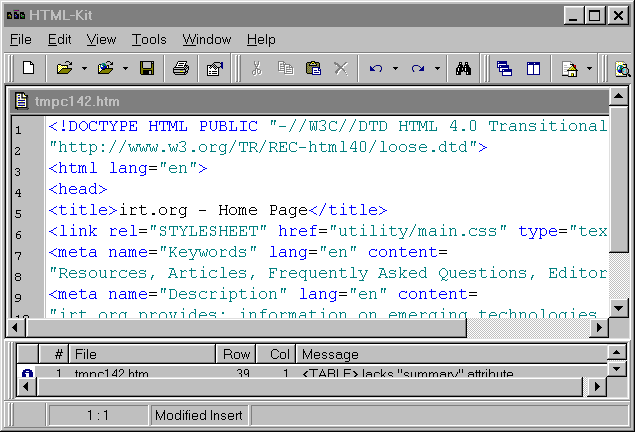
Figure 1. HTML-Kit Interface.
As with the case of online validation, your HTML document may again contain unnecessary characters. HTML (Un)Compress is a shareware program which optimizes your HTML document by removing such characters. It is available for Windows 95/98/NT-based platforms. The most important feature of HTML (Un)Compress is that, besides reducing the size of your document, it preserves the formatting of the document - its Compress tool first removes all information used for editing in the HTML file and then the UnCompress function of this tool adds this formatting information once again.
To err is an HTML author; to forgive is the browser.
HTML authoring is error prone and consequences of this (HTML-version of a biblical) maxim are damaging - although you can check your documents using a WWW browser, this may not reflect all the errors in the document because some browsers are quite forgiving and can recover from errors.
It is important that any document, whether in a formal or informal language, be syntactically, semantically and stylistically correct. HTML is no exception. Online or offline HTML validators can be quite useful in this endeavour, before there is a need for damage control.
Internet Explorer As A Development Platform?
META tags: What they are and how they work
HTML #5 - Using feedback forms
HTML #4 - Advanced Page Layout
HTML #3 - Making your Web pages more exciting