Multi-dialogue forms on one page
Turning Tables Into Selection Lists
You are here: irt.org | Articles | Dynamic HTML (DHTML) | A Gift of "Life" : The Document Object Model [ previous next ]
Published on: Friday 15th January 1999 By: Pankaj Kamthan
The perception and nature of the term "document" has changed over the time. In the early years of the WWW, a document was a container of static information. Even until recently, for dynamicity or for user-interaction, one had to write applications in Java/CGI, or use a plug-in/Active X control. The document was often an end result of an application.
With the introduction of client-side event-handling scripting languages such as JavaScript, the nature of documents changed from passive to active. The documents themselves became "live" applications.
If documents are becoming applications, we need to manage a set of user-interactions with a body of information. The document thus becomes a user-interface to information that can change the information and the interface itself.
HTML itself is a static data format; how the browser renders the various elements of an HTML page is a behaviour that is pre-defined. We can change these behaviours to create and control new kinds of behaviours by defining them in scripts (for example, using JavaScript) or as formatting properties using Cascading Style Sheets (CSS).
eXtensible Markup Language (XML) is increasingly being used as a way of representing many different kinds of information that may be stored in diverse systems, and much of this would be seen as data rather than as documents. Nevertheless, XML presents this data as documents.
As we will see later, the DOM is the underlying foundation for the change of nature and view of a document as interactive "living" data.
Ask not what you can do for the browser, ask what the browser can do for you
With HTML 4.0, authors now have a standard way to embed scripts and styles in their documents. This will eventually allow them to dynamically access and update their content, structure, and style. One effort to provide such a powerful mechanism has been termed as "Dynamic HTML". It has been used by some vendors such as Netscape and Microsoft to describe the combination of HTML, style sheets and scripts that allows documents to be manipulated.
However, implementations under the umbrella of "Dynamic HTML" are not only proprietary but also incompatible. For example, JavaScript is proprietary to Netscape and its implementation by Microsoft (JScript) is different. Microsoft's VBScript (based on their own language Visual Basic) is supported by their browser Internet Explorer but not by Netscape Communicator. Netscape's implementation of CSS differs from that of Microsoft, and neither are complete. In such cases, to retain compatibility, one is forced to resort to the common denominator, or worse, provide different copies of the document (along with the scripts and styles) corresponding to different browsers. As a result, in the absence of a standard interface, authors are unable to write programs that work without changes across vendors. This is in contrast to the motivation behind various (interoperable) technologies that brought the WWW into existence in the first place.
An object model is a framework that organizes how behaviours are referenced and how they act upon information and interact with each other. For example, how scripts reference elements of a document, how styles are applied to elements, and how scripts change styles or how styles initiate scripts. See Figure 1. The DOM is one such object model.
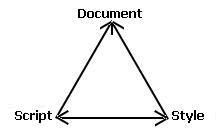
Figure 1: A relationship between the document, a style and a script
in an object model. Arrows indicate the interactions between these components.
The DOM originated as a specification to solve the problems mentioned above with "Dynamic HTML" and allow JavaScript scripts and Java applets to be portable among WWW browsers. The purpose was to have an object model of HTML documents that can be exposed to scripts. During this development, XML evolved as a "simplified" version of Standard Generalized Markup Language (SGML) for the WWW (to solve limitations associated with HTML). This brought various notable standards (SGML Grove and HyTime) and proprietary object models for documents based on SGML and XML into play. These standards and object models also influenced the DOM.
The DOM is being designed to be extensible, in form of layers. The current state of the DOM has evolved as follows:
For the purposes of this article, by any reference to the DOM, we mean the DOM according to the DOM Level 1 Specification, unless stated otherwise.
Our purpose is to facilitate "exposure" of document elements to scripts. Exposing document elements refers to the process of defining the elements and their attributes in such a way as to be presented to the scripting languages. The DOM uses an object-oriented approach to this problem. Next section will help us understand some of the inner workings of the DOM.
A document is an ordered collection of elements. An element is an object that contains all the content between the start and end tags of the element as objects, and any set of attributes that are defined for the element.
How can the scripts identify an element? Each element can be assigned a name (its tagname). For example, we can assign the H2 element an ID attribute that uniquely identifies it:
<H2 ID="foo">OBJECTS, OBJECTS AND MORE OBJECTS</H2>
Using this scheme, you can get a list of, for example, all the H2 elements in the document. On the other hand, by following the style of assignment:
<H2 CLASS="bar">OBJECTS EVERYWHERE</H2>
you can get a list of all the elements with the attribute CLASS="bar".
How can scripts locate an element? Each element object (parent) contains other element(s) (child). For example, in an HTML document, the <HEAD> element typically contains a <TITLE> element. Child objects inherit attributes from its parent elements. This results in a view of the document as an object hierarchy and also gives us a way to navigate around within the document structure.
How can scripts manipulate an element? This is where viewing elements of a document as objects becomes really useful. An important characteristic of objects is that you can reference them and their contents. Behaviours access and manipulate objects and their contents. Such behaviours can be triggered using scripts - once scripts can reference the objects and their contents, they can also manipulate them.
For example, (using the current implementation of DOM Level 0) JavaScript allows you to reference the title of a document as document.title.
The title of this document is:
The convention as to how the behaviours should be referenced is defined by an object model, such as the DOM.
According to the recommendation, the DOM is defined as follows:
The Document Object Model is a platform- and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure and style of documents
The DOM consists of two parts: DOM Core and DOM HTML. The DOM Core represents the functionality needed for XML documents to manipulate hierarchical document structures, elements, and attributes, and also serves as the basis for DOM HTML. The functionality that depends on the specific elements defined in HTML are given in DOM HTML section. We now present two views of the DOM.
An API describes the handles that are used to reference objects and their methods. DOM is an API for HTML and XML documents. It provides a standard set of objects for representing HTML and XML documents, a standard model of how these objects can be combined, and a standard interface for accessing and manipulating them. It defines the logical structure of documents and the way a document is accessed and manipulated.
The object model in the DOM is a programming object model that comes from object-oriented design (OOD). It refers to the fact that the interfaces are defined in terms of objects. The name "Document Object Model" was chosen because it is an "object model" in the traditional OOD sense: documents are modeled using objects, and the model encompasses the structure as well as the behaviour of a document and the objects of which it is composed. As an object model, the DOM identifies:
The DOM, despite its name, is not an object model in the sense of other familiar standards such as the Component Object Model (COM) or Common Object Request Broker Architecture (CORBA). (The COM or CORBA, are language independent ways to specify interfaces and objects; the DOM is a set of interfaces and objects designed for managing HTML and XML documents. The DOM may be implemented using language-independent systems like COM or CORBA. It may also be implemented using language-specific bindings.)
HTML allows authors to structure documents into headings, paragraphs, hypertext links and other component parts. DOM is a standard internal representation of the document structure and makes it easy for programmers to access those components and manipulate their content, attributes and style. Some advantages of the DOM are:
Models are structures. The DOM closely resembles the structure of the documents it models. In the DOM, documents have a logical structure which is very much like a tree. To be more precise, it is like a grove, as it can contain more than one tree. As an example, consider the table taken from an HTML document:
<TABLE>
<TBODY>
<TR>
<TD>a11</TD>
<TD>a12</TD>
</TR>
<TR>
<TD>a21</TD>
<TD>a22</TD>
</TR>
</TBODY>
</TABLE>The DOM representation of the table is shown in Figure 2:
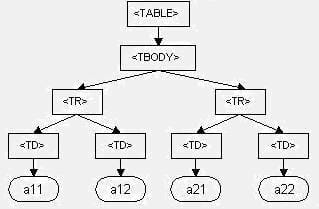
Figure 2: The DOM representation of the table
The DOM does not specify that documents must be implemented as a tree or a grove, nor does it specify how the relationships among objects be implemented. The DOM is a logical model that may be implemented in any convenient manner. Therefore, the term structure model is used in the DOM specification to describe the tree-like representation of a document in order to avoid implying a particular implementation.
The document structure model defines an object hierarchy made up of a number of nodes. As an example, Figure 2 is the DOM representation of the table as a structure model (actually, a tree) of nodes which represent objects, that have functions (methods) and identity (properties). The Node object is a single node on the document structure model and the Document object is the root node of the document structure model and provides the primary access to the document's data. The Document object provides access to the Document Type Definition (DTD) (and hence to the structure), if it is an XML document. It also provides access to the root level element of the document. For an HTML document, that is the <HTML> element, and in an XML document, it is the top-level element. It also contains the factory methods needed to create all the objects defined in an HTML or XML document.
Each node of the document tree may have any number of child nodes. A child will always have an ancestor and can have siblings or descendants. All nodes, except the root node, will have a parent node. A leaf node has no children. Each node is ordered (enumerated) and can be named. The following example illustrates this hierarchy:
Section 1 - Parent of Section 1.1/Ancestor of Section 1.1.1
Section 1.1 - Parent of Section 1.1.1
Section 1.1.1 - Leaf node/Child of Section 1.1/Descendant of Section 1
Section 1.2 - Sibling of Section 1.1The DOM establishes two basic types of relationships:
The structure of the document determines the inheritance of element attributes. Thus, it is important to be able to navigate among the node objects representing parent and child elements. Given a node, you can find out where it is located in the document structure model and you can refer to the parent, child as well as siblings of this node. A script can manipulate, for example, heading levels of a document, by using these references to traverse up or down the document structure model. This might be done using the NodeList object, which represents an ordered collection of nodes.
Suppose, for example, there is a showcase consisting of galleries filled with individual images. Then, the image itself is a class, and each instance of that class can be referenced. (We can assign a unique name to each image using the NAME attribute.) Thus, it is possible to create an index of image titles by iterating over a list of nodes. A script can use this relationship, for example, to reference a image by an absolute or relative position, or it might insert or remove an image. This might be done using the NamedNodeMap object, which represents (unordered) collection of nodes that can be accessed by name.
The above mentioned node objects are from the DOM Core. DOM HTML provides objects specific to HTML.
There are various possible applications of the DOM. The browser you use may implement a JavaScript/VBScript interface, so you can use those scripting languages within the document itself to manipulate the document or change the CSS style sheet (see, for example, the article Dynamic StyleSheets). This is already possible due to the DOM Level 0 with JavaScript/VBScript-enabled pages, and you may already be familiar with many such applications. We also discussed some trivial examples in previous sections.
As implementations of DOM Level 1 become widespread, many other applications may be realized. Indications of some such possible applications are mentioned in the DOM FAQ.
The DOM is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents in a standard way. This standard interface will make scripting reliably across platforms a reality. Viable cross-platform implementations of this interface are yet to be seen.
The W3C DOM Working Group completed Level 1 in October 1998, which is now a W3C Recommendation. Work on Level 2 has started. It is being planned in Level 2 to include a style sheet object model, and define functionality for manipulating the style information attached to a document. For example, it will allow manipulation of the CSS styles attached to an HTML or XML document. It will also allow rich queries of the document and include an event model. Other levels are also planned; see the W3C Activity Statement on the DOM.
To keep abreast with the latest activities you can visit the (official) W3C DOM page. You can also subscribe to their mailing list (see the references).
The DOM is a model in which the document contains objects. Each object has properties and methods associated with it that can be accessed by a scripting language for manipulation.
If the network is the computer, then the browser is an operating system user-interface of that computer. If a document is a user-interface to information accessible through the browser, then the DOM is a framework that organizes how behaviours associated with the user-interface are referenced, and how they act upon information and interact with each other.
DOM is the "Dynamic" of Dynamic HTML
The word dynamic can have different interpretations, from physical and from social points of view: in motion (text or image swap when mouse pointer moves over, animations, etc.) or non-static (that is, flexibility, when it comes to the choice of a platform, an operating system, a browser, etc.). The use of the DOM may bring true meaning to the term "Dynamic HTML" through interoperability in an open networking environment (with platform, operating system, programming language, server and browser-independence).
It is pointed out in the webreview.com series of articles on applications of "Dynamic HTML" that "The possibilities are endless ... if we can only get a cross-browser version of the DOM that worked." That solution has just arrived.
This Appendix gives a glossary of selected DOM-related terms. Most of these term definitions have been adapted from The Document Object Model Level 1 Recommendation with minor changes and a few new additions.
ITEM |
DEFINITION |
| ancestor | An ancestor node of any node N is any node above N in a tree model of a document, where "above" means "toward the root." |
| API | An API is an application programming interface, a set of functions or methods used to access some functionality. |
| child | A child is an immediate descendant node of a node. |
| COM | COM is Microsoft's Component Object Model, a technology for building applications from binary software components. |
| CORBA | CORBA is the Common Object Request Broker Architecture from the OMG . This architecture is a collection of objects and libraries that allow the creation of applications containing objects that make and receive requests and responses in a distributed environment. |
| descendant | A descendant node of any node N is any node below N in a tree model of a document, where "above" means "toward the root." |
| ECMAScript | The programming language (as a result of the effort of standardization of JavaScript/JScript by ECMA) defined by the ECMA-262 standard. |
| element | Each document contains one or more elements, the boundaries of which are either delimited by start-tags and end-tags, or, for empty elements by an empty-element tag. Each element has a type, identified by name, and may have a set of attributes. Each attribute has a name and a value. |
| IDL | An Interface Definition Language (IDL) is used to define the interfaces for accessing and operating upon objects. Example of an IDL is the Object Management Group's IDL . |
| inheritance | In object-oriented programming, the ability to create new classes (or interfaces) that contain all the methods and properties of another class (or interface), plus additional methods and properties. |
| interface | An interface is a declaration of a set of methods with no information given about their implementation. In object systems that support interfaces and inheritance, interfaces can usually inherit from one another. |
| language binding | A programming language binding for an IDL specification is an implementation of the interfaces in the specification for the given language. |
| leaf | A leaf is node which has no children. |
| method | A method is an operation or function that is associated with an object and is allowed to manipulate the object's data. |
| model | A model is the actual data representation for the information at hand. Examples are the structural model and the style model representing the parse structure and the style information associated with a document. The model might be a tree, or a directed graph, or something else. |
| object model | An object model is a collection of descriptions of classes or interfaces, together with their member data, member functions, and class-static operations. |
| parent | A parent is an immediate ancestor node of a node. |
| root node | The root node is the unique node that is not a child of any other node. All other nodes are children or other descendents of the root node. |
| SGML | A meta-language of which HTML is a DTD. |
| sibling | Two nodes are siblings if they have the same parent node. |
Multi-dialogue forms on one page
Turning Tables Into Selection Lists
Drag and Drop with Microsoft Internet Explorer 5