Perspectives of XML in E-Commerce
XML Entities and their Applications
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
You are here: irt.org | Articles | Extensible Markup Language (XML) | XML Conformance : The Burden of Proof [ previous next ]
Published on: Sunday 13th August 2000 By: Pankaj Kamthan
XML is emerging as a mechanism for both data interchange between applications and document publishing on the Web. One of the major advantages of XML over SGML is that it enforces structuredness by imposing well-formedness. XML, unlike SGML, has no optional features. An XML document must be well-formed (if it is not well-formed, by definition, it is not an XML document) and in several crucial cases should be valid (conform to a specified schema, expressed formally in the DTD (document type definition)).
However, as historically seen with HTML, there is a possibility that the "rules" set by the XML 1.0 Specification may not be followed in documents that are authored. This poses a major threat to the Web architecture, with an apparent danger that this will only add to the chaotic situation of the Web. If that happens, there will be a lack of user-agent interoperability and obstacles to a transparent information exchange, thus neutralizing the advantages that XML offers. Thus, testing the documents for conformance before they are published, is crucial.
This article attempts to answer several questions that need to be asked in the context of conformance:
Why validate? What does well-formedness/validation mean? What exactly (in the document) is being validated? How to test documents for well-formedness or validate?
It is assumed that the reader has a basic familiarity with XML syntax, though an exhaustive background is not required.
There are three types of XML documents possible:
Figure 1 provides an illustration of these relationships.
The Universal Set Of Documents
|
Figure 1. XML Document Universe.
Conformance to standards is significant from the point of view of interoperability, which is the basis of transparent communication in the "open" networking environment of the Web. The notion of XML "conformance" is addressed directly in the XML 1.0 Specification in 5. Conformance. The term "conformance testing" as it pertains to a standard has appeared in several ISO documents (ISO/IEC DIS 10641, ISO/IEC TR 13233) under varying definitions. The two main conclusions that can be drawn are:
In our context, "XML conformance" is used is a generic sense where it applies both to a candidate document (that is in XML syntax) and to a candidate program (that implements XML, that is, it is an XML processor). This dual categorization for conformance is used, for example, in Scalable Vector Graphics (SVG), which in its SVG conformance criteria includes Conforming SVG Documents as well as Conforming SVG Generators, Conforming SVG Interpreters, and Conforming SVG Viewers.
Well-formed (only) XML documents are useful for several reasons. If documents are
non-well-formed, it may lead to unexpected results, such as, they may not be rendered
properly or not at all (depending on the XML processor, which is required to detect and
report any well-formedness error but not required to continue processing in a normal way).
Well-formed XML documents do not require the author to be familiar with the DTD syntax,
and therefore require less expertise, and less time and effort for authoring. This can
work well in a single-user (in this case, the author) contexts. It also makes the size of
XML documents smaller though still structured. For example, when authoring XSLT style
sheets explicit association of a DTD (using a DOCTYPE declaration) is not
always necessary. (The style sheets may still be valid but are served as well-formed XML
documents.)
XML validation is an important part of authoring. Validation on the client side, such as rendering in a browser is not necessary (unless the browser requires it explicitly), since if it is invalid, the browser will not change that fact. However, validation on the delivery-side in the machine-machine communication where data needs to be entered directly into, say, a database, becomes necessary. For example, a company B receiving data from a company A would like to have a "checkpost" prior to having it enter their systems to avoid corrupting their own data. There are several other benefits of validation in the E-Commerce setting.
There are several approaches to XML conformance: Content Model-based, Tree Location-based (using XSL and XPath), Regular Expressions-based. However, we will restrict ourselves to the discussion of the content model-based approach as it has been well-tested and implementations for it are widely available.
We can classify XML conformance techniques into two broad categories: "Desktop" XML Conformance and "Network" XML Conformance. These techniques make use of (validating and non-validating) XML processors which are software that can help in testing a candidate XML document for conformance. The software that are chosen for this article are primarily based on the features they offer and availability, and to illustrate a variation (different vendors, different platforms, different languages). This should not taken to imply that other software are less important. In fact, the software discussed here are representative and a transition to other software should be readily possible.
By a "desktop" XML conformance, we mean testing a document for XML well-formedness and/or validity locally. This is accomplished in two ways:
By a "network" XML conformance, we mean testing a document for well-formedness and/or validity over the network. This is realized by using an XML conformance service.
Some well-known examples of such services are XML Checker using RXP, RUWF, STG Validator, DOMit, Microsoft XML Validator, X-Ray, DoXML. They may offer any one or more of the three types of interfaces:
Table 1 presents a summary of the tools mentioned in I, II and III above. Detailed discussions of each are carried out in appropriate sections.
| Tool | Type | WF/V | Miscellanous Features |
| XML Spy | Authoring Environment | WF and V | |
| XMetaL | Authoring Environment | WF and V | |
| XP | Standalone XML Parser | WF | |
| XML4C | Standalone XML Parser | WF and V | |
| RUWF | XML Conformance Service | WF | URL-Based |
| XML4J as a XML Conformance Service | XML Conformance Service | WF and V | Text Area-Based |
| DOMit | XML Conformance Service | WF and V | Text Area-Based, Constructs a DOM 1.0 Tree |
| STG Validator | XML Conformance Service | WF and V | URL-Based, File Upload-Based, Text Area-Based |
| Legend: WF := Well-Formedness Support, V := Validation Support. | |||
Table 1. A Summary of XML Conformance Tools.
Remarks
The above categories are not necessarily functionally distinct. Some XML authoring environments do come bundled with well-known XML parsers (which are also available as standalone). For example, XML Spy uses the Microsoft XML Parser (msxml) for validation. Gateway services such as DOMit use XML4J as the back-end parser, while RUWF uses the Lark parser.
The advantages of using a "desktop" XML conformance approach are obvious. The main disadvantage is affordability: high-end XML authoring environments that have a rigorous support for XML conformance are usually not freely available. The environments which are freely available may not have all the bells and whistles of a commercial software, and may have only a moderate support for XML conformance.
The advantage of using a "network" XML conformance approach is that all that is required is the browser and one is not burdened with its maintenance (monitoring the service, carrying out any upgrades). It also frees the user (and the load on the system) from the tedium (and, in some cases, cost) of installing the software (if available), requirements of which can sometimes be recursive (the required software in turn requires installation of other software). The disadvantages are that the user does not foster any control, the service may cease to continue, loss of privacy (as the document is "open"), not very practical for large documents, and one needs to be online in order to use the service.
Note that any tools that are used for XML validation setting, can also be used for the purposes of well-formedness checking. Therefore, we will defer the discussion of such in the section on XML Validation Testing.
XP is a high performance XML parser in Java. It is fully XML conforming; it detects all non well-formed documents (but is currently not a validating XML processor). XP supports a variety of Unicode encodings.
The XP distribution includes several sample programs. One of these programs is Time,
which parses the document and prints the amount of time required to parse the DTD and the
document. Under an operating system with a shell environment (Windows 9x/NT, Unix, Linux),
and assuming that the JAR file xp.jar is in the CLASSPATH, it
can be used as follows:
>C:\XML\XP>java com.jclark.xml.apps.Time wwwc_logo.xml 0.93
The result states that it took 0.93 seconds to parse the document wwwc_logo.xml. This indicates that the document is well-formed.
If the document is malformed (such as, r12n_pe.xml) additional error messages are displayed:
C:\XML\XP>java com.jclark.xml.apps.Time r12n_pe.xml r12n_pe.xml:5:10: character not allowed 0.88
RUWF is a XML well-formedness checker at the XML.com Web site. You can type in the URL of a document below, and check to see whether it is well-formed. RUWF is based on the Lark parser, one of the earliest "proof-of-concept" non-validating parser.
See the section on XML Conformance Error Diagnostics in XML Conformance Services for more details.
The fact that XML requires well-formedness but makes validation optional should not mean to imply that validation is less significant. The freedom that "everybody can create their own tags" provided by XML comes at a price. Well-formed (only) documents can be quite useless, as shown in the following well-formed document:
<quote><para><colour>brown</colour> jumped the The <animal>fox</animal>. quick over <animal>dog </animal> lazy </para></quote>
In this case, although the document is well-formed, it is virtually meaningless, and difficult to interpret (especially by a machine). Thus, XML documents that are merely well-formed can store any element in any order and/or adjacent to any other element, which is usually not very helpful. Validation of XML documents helps ensure that the information is structured in a way that is sensible for applications which use it. The need for validation becomes all the more pressing when there are various stakeholders (human or machine), who need to work closely to unambiguously exchange data.
XML Spy
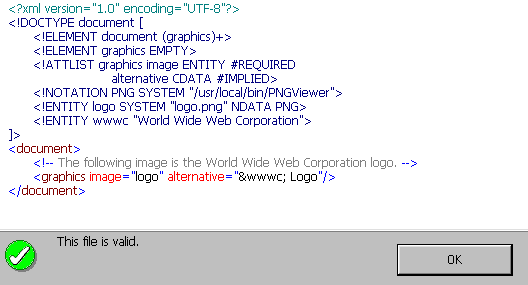
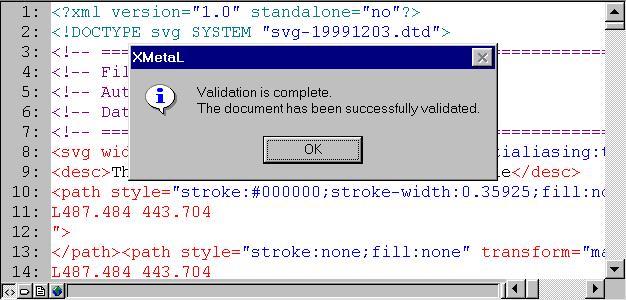
is a commercial XML editor with XML well-formedness and validation support. It provides three advanced views of the documents: an Enhanced Grid View for structured editing, a Source View with syntax-coloring for low-level work, and an integrated Browser View. Here is a sample XML Spy screenshot for a validation test for the document wwwc_logo.xml. See the section on XML Conformance Error Diagnostics in XML Authoring Environments for more details.XMetaL is a commercial SGML/XML editor with XML well-formedness and validation support. Among its various features, it support DTDs in ASCII and compiled form, three views of the document: Normal, Plain Text, and Tags On. Here is a sample XMetaL screenshot for a validation test for the document cgi.svg. See the section on XML Conformance Error Diagnostics in XML Authoring Environments for more details.
XML4C is a validating XML parser in C++ that claims to fully conform to the XML 1.0 Specification. It has support for several other XML-related initiatives, including DOM 1.0, SAX 1.0, XML Namespaces, XML Schemas, XPointer and XCatalog. It also supports a large number of Unicode and EBCDIC character encodings, and ISO entities.
The XML4C distribution includes several sample programs. Some of the useful programs
are SAXCount (it counts the elements and characters of
a given XML file using the (event based) SAX API), SAXPrint (it uses
the SAX APIs to parse an XML file and print it back), DOMCount (it uses the
provided DOM API to parse an XML file, constructs the DOM tree and walks through the tree
counting the elements using just one API call) and DOMPrint (it parses an XML
file, constructs the DOM tree, walks through the tree printing each element with the
output same as SAXPrint).
All of these programs can be used (with the option -v) to test the validity of XML
documents. We now present a few examples (that use executable version of these programs
under Windows). The following is an example that uses SAXCount:
C:\XML4C\bin\>SAXCount.exe -v wwwc_logo.xml wwwc_logo.xml: 16 ms (2 elems, 2 attrs, 5 spaces, 0 chars)
As shown above, it took 16 milliseconds for the program to parse. Details about the document (number of elements, attributes, and so on) are given in the parenthesis.
The next example shows a response by using SAXPrint on the document wwwc_logo.xml. This is the same as using DOMPrint,
where one gets the entire document minus the XML and DOCTYPE declarations:
C:\XML\XML4C\bin>SAXPrint.exe -v wwwc_logo.xml <document> <graphics image="logo" alternative="World Wide Web Corporation Logo"></graphics> </document>
Running DOMCount on the same document as in:
C:\XML\XML4C\bin>DOMCount.exe -v wwwc_logo.xml wwwc_logo.xml: 35 ms (2 elems).
took 35 milliseconds, almost twice the time taken by SAXPrint. This shows
that even for a small document, traversing the tree (as in DOMCount) can take
a longer time than serial access (as in SAXCount). This time difference is
nonlinear and only increases with larger documents.
This is what is obtained when a non-well-formed document r12n_pe.xml
is parsed using DOMPrint:
C:\XML\XML4C\bin>DOMPrint.exe -v r12n_pe.xml Fatal Error at file "r12n_pe.xml", line 5, column 11
XML4J is a validating XML parser
in Java that claims to fully conform to the XML 1.0 Specification. It is available as an
XML conformance service which can be used to test a document for XML well-formedness or
validity. You may refer to the DTD from an XML document via a URI or via the DOCTYPE
declaration. When the Parse button is pressed, a copy of XML4J is
instantiated which parses the document and returns the results. If there are any errors,
they are pointed out, and once fixed, the process can be repeated. See the section on XML Conformance Error Diagnostics in XML
Conformance Services for more details.
DOMit, a Java servlet, is a tool for quickly determining the validity of a document and then displaying its structure. DOMit executes the XML4J parser to assess the validity. If the document passes the parser test, DOMit displays the XML document in your browser window. It creates an HTML tree view of the Document Object Model (DOM) which can be navigated. If the document fails the parser check, DOMit tells you what is missing. You can then edit and resubmit it for validation.
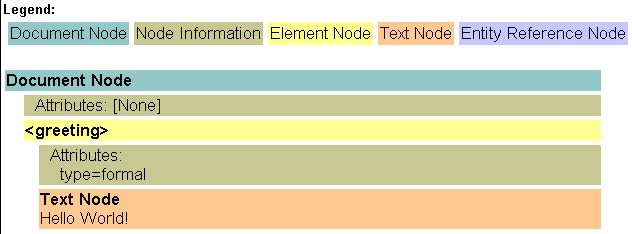
Here is the DOM tree created by DOMit on the document greeting.xml. See the section on XML Conformance Error Diagnostics in XML Conformance Services for more details.
STG validator is an online service hosted at Scholarly Technology Group (STG) Web Site to check XML documents for well-formedness as well as validity. It offers the options by which it can access a candidate XML document: via a URL, File Upload, or entering it in a text area. There is an FAQ and detailed documentation available. It provides warnings about ambiguous content models and has experimental support for XML namespaces. STG Validator deviates from the XML 1.0 Specificaiton in whitespace handling, which it ignores inside of markup where syntactically irrelevant. Another caveat is that all results are encoded as UTF-8. See the section on XML Conformance Error Diagnostics in XML Conformance Services for more details.
XML validation based on a DTD can be inexact and misleading. DTD-based validation checks only syntax, one can still have semantic errors. For example, the following SVG document is valid but leads to a semantic ambiguity (radius of negative length) due to weak DTD datatyping:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG December 1999//EN" "http://www.w3.org/Graphics/SVG/svg-19991203.dtd"> <svg width="4in" height="3in"> <g><circle cx="200" cy="200" r="-100"/></g> </svg>
This situation is expected to improve with the adoption of XML Schema, with content model validity (to test whether the order and nesting of tags is correct) and datatype validity (to test whether specific units of information are of the correct type and fall within the specified legal values). However, providing general data structure is not within their scope and the effort is yet to be standardized.
The practice of validation is more mature in programming languages, such as, during the compiling process. There are tools, for example, debuggers which can then be used to fix those errors. There is a lack of such comprehensive debuggers in markup languages; one has to often resort to human effort to eradicate the errors.
One indication of XML's success is that several implementations of an XML processor exist. The question then arises is: Are XML processors doing what they claim to do, supposed to do, or will they create islands of data that can only be used with a single set of tools (which is not very different than the situation of being locked into using a proprietary format)? One way to answer these questions is to design a rigorous test suite and carry out a conformance testing.
OASIS (The Organization for the Advancement of Structured Information Standards, USA) in association with NIST (National Institute of Standards and Technology, USA) set up an XML Conformance Subcommittee that has delivered a OASIS XML Conformance Test Suite. The test suite is available for download and can serve as a useful aid for testing different XML processors as a basis of making a judicial choice. As an example, a conformance testing for Java-based XML parsers, based on this suite, has been carried out to evaluate how closely the parsers follow the XML 1.0 Specification.
XML document engineering (from design, to authoring, to testing, to publishing) is an iterative process. To err is the author, and the act of parsing an XML document can result in error responses. Indicating only that "the document is not well-formed and/or not valid" is of little use, particularly for large documents.
Fortunately, even though every parser produces slightly different error messages, they usually indicate what is incorrect (at least from a technical viewpoint). Some also indicate where the error occurred. This information serves as a useful prerequisite to identify the errors as well as how to rectify them. Note, however, that this is a departure from WYSIWYG-type authoring and the author is expected to understand the basics of XML syntax to interpret the results and make any use of them. This may be a disadvantage to those using "visual editors", which is often the case in use for XML vocabularies such as MathML, SVG and SMIL. Nevertheless, the issue of creating XML conformant documents remains important.
A useful feature of some of the authoring environments (such as XML Spy and XMetaL) is
that when errors are found, they are highlighted (by use of colours or by placing
the cursor in the editing environment at the point where the first error is encountered).
This process repeats with subsequent tests for conformance. This can significantly reduce
the document production cycle, particularly when authoring large documents. Both XML Spy
and XMetaL also provide details such as Whitespace Expected and possible
options (Tab, CR, and so on). XML Spy provide details such as <!ELEMENT Expected,
when there is an error in the internal DTD subset and the corresponding production rule
from the XML EBNF notation, when
it finds a malformed tag.
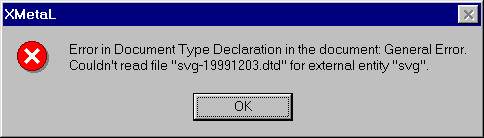
Authoring environments such as XMetaL are very strict with documents that are malformed and may not even open them in the editor, which results in a "circular problem" of authoring (if the document can not be opened for editing, it can not be corrected). For example, if XMetaL can not find an associated DTD, it will not open the document and issue an error.
Standalone XML parser usually provide the most details in their error messages. Examples presented previously in sections on XP and XML4C provide an indication of this.
SGML parsers, which have stood the test of time and as a result are fairly robust, can also be used for XML conformance. As an example, parsing error messages for use of SP with DocBook (SGML) documents have been described in detail in. Although, the discussion is SGML-based, many of the results apply to XML documents as well. Some of results such as Invalid 8-Bit Character do not always apply to XML documents, since the range of Unicode characters is far larger than that available in SGML.
Error diagnostics of XML conformance services are similar to those found in case of publicly available standalone XML parsers, if the services are based on them.
RUWF provides a detailed report that includes the line number and column of each error
it encounters, along with a (human) readable description such as: Line 2, column 51:
PI target cannot match 'xml'.
A useful feature of the XML4J as a XML Conformance Service is that it not only highlights the errors (by use of colours and indicating the line number(s)), but also includes the URL of the relevant section in the XML 1.0 Specification that has been violated.
Error messages of DOMit are similar to that of XML4J as a XML Conformance Service but it highlights the errors a bit differently (indicating the line and column numbers of corresponding error positions).
When errors are encountered in an XML document, the STG Validator includes a copy of the original document with line numbers associated with each line of the document and provides verbose listing with description of errors corresponding to the lines where the error(s) have occurred. The results in STG Validator are displayed as follows: If no errors are found, a "Document Validates OK" message is displayed, possibly accompanied by a list of warnings. If errors are found, a list of them is printed out. If any of these errors occurs in the document itself (as opposed to an external file), the document with line numbers (associated with each line of the markup) is appended, with links to the relevant error messages corresponding to the lines where the error(s) have occurred.
The use of XML software for conformance should be made with care and results obtained from them should be seen objectively for several reasons:
Conformance is Not an Option
Correctness is a subjective term, for which the scale is provided by standards. The task of authoring XML documents, and testing for conformance with respect to the guidelines outlined by the standard in question, go hand in hand. By avoiding ad hoc methods of authoring and publishing, and following the norm provided by standards, the authors can indeed help build the foundation of a Semantic Web.
This work did not include the issue of conformance with respect to other important areas such as Web Accessibility, an issue that is being treated separately in the XML context. Another key area that has not been discussed above is implementation conformance, that is, conformance testing of XML processors. See the list of references for details.
I would like to thank Richard Goerwitz, author of the STG Validator, who pointed out in a feedback to the article "Stop! Is Your HTML Document Valid?" that "the issue of validation in the XML world is as pressing as it is in the HTML world" and thus inspired this work.
Perspectives of XML in E-Commerce
XML Entities and their Applications
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}